
Short AI
Short AI 是一款全能型 AI 视频创作平台。它的核心理念是让视频制作变得极简。通过 AI 技术,它能将长视频一键切片、将文字脚本转化为引人入胜的故事,并自动完成字幕添加、视觉增强和跨平台排期发布。
LOADING
在数字化办公和 AI 大模型飞速发展的今天,我们依然面临一个巨大的“天堑”:PDF 格式。
无论是学术论文中复杂的双栏排版、层层嵌套的数学公式,还是报告里横跨两页的表格,PDF 就像一个“信息黑匣子”。传统的 OCR(光学字符识别)往往只能提取文字,却丢掉了结构。
今天,我们要聊的是一款正在 GitHub 上悄然走红、由 OpenDataLab 推出的开源神器——MinerU(一站式 PDF 文档解析工具)。
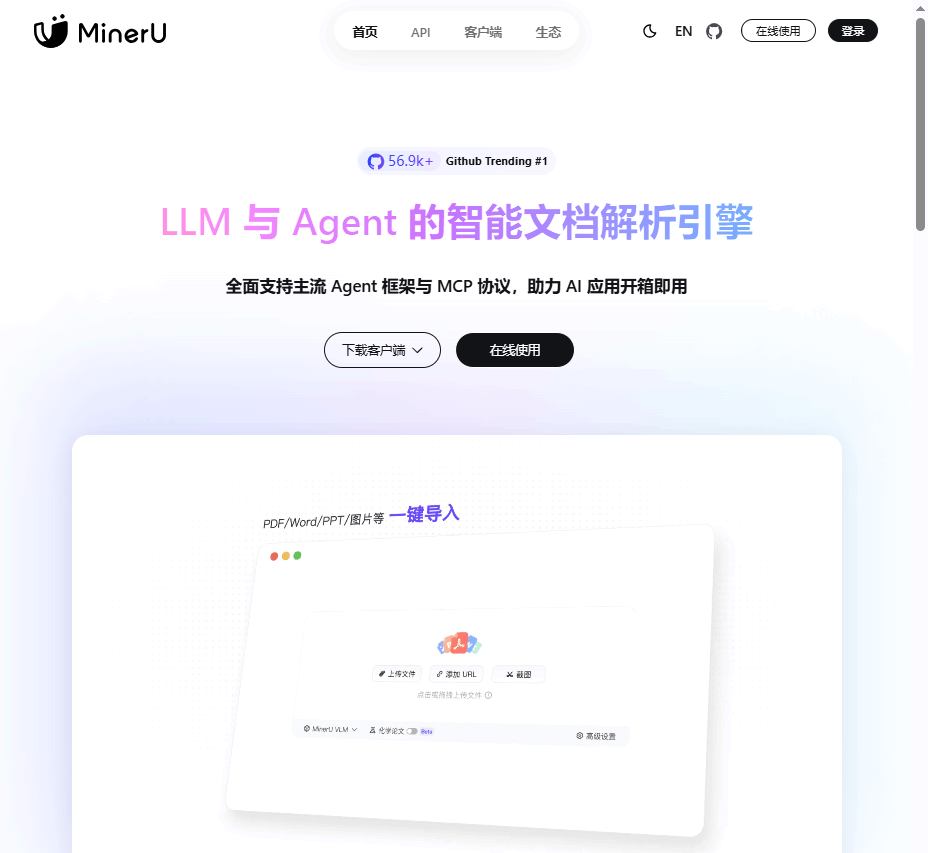
MinerU 网站截图
市面上不乏 PDF 转 Word 工具,但 MinerU 的逻辑完全不同。它是为了 “让 AI 读懂人类文档” 而生的。
传统的解析工具基于规则(Rule-based),一旦遇到非标准排版就乱码。MinerU 采用了多模态模型:
精准布局分析:它能像人类视觉一样,自动识别页眉、页脚、正文、插图和表格。
自动去噪:剔除无关的浮水印、边框干扰,只留下最核心的干货。
这是科研狗和理工男的福音。MinerU 能将 PDF 中复杂的数学公式直接转化为 LaTeX 源码。 想象一下,你再也不用对着论文里的微分方程手打代码,MinerU 一次扫描,公式直接进论文草稿。
如果你在折腾本地知识库(LlamaIndex 或 LangChain),你会发现 PDF 的解析质量直接决定了 AI 回答的准确度。MinerU 支持将 PDF 转化为高标准的 Markdown 格式,保留了层级标题和表格结构,让大模型阅读起来“如丝般顺滑”。
全自动转换:支持 PDF 转 Markdown、JSON 等开发者友好格式。
多语言支持:对中英文的识别准确率处于行业第一梯队。
开源开放:作为 OpenDataLab 体系的一部分,MinerU 拥有活跃的社区支持,且允许本地化部署,保障了敏感数据的隐私安全。
科研工作者:快速整理海量文献,提取公式和实验数据。 AI 开发者:为大语言模型准备高质量的清洗后语料。 企业数据治理:将堆积如山的扫描版合同、财报转化为可搜索、可计算的结构化数据。
MinerU 的使用门槛极低,却上限极高:
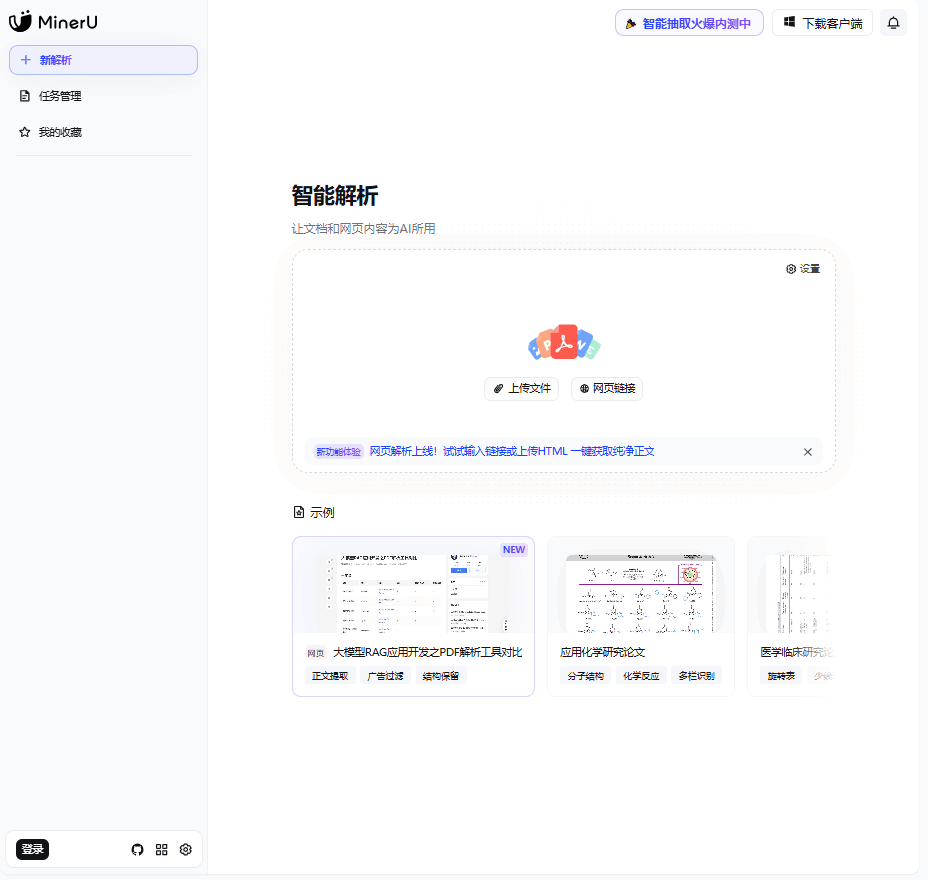
在线体验:直接访问 mineru.net,上传文档即可见证奇迹。
本地部署:对于有大批量处理需求的极客,可以通过 pip 轻松安装其开源版本,直接调用其推理框架。
PDF 不应该是通往通用人工智能(AGI)道路上的阻碍。MinerU 的出现,本质上是在做一场“数字考古”——它将那些被困在静态像素里的知识,重新转化为流动的、可计算的信息。














